|
|
|
dtSearch enterprise and developer products instantly search terabytes of text (including 25+ search options). dtSearch’s own document filters support files, emails, databases and web data. SDKs cover multiple platforms. See
dtSearch.com for hundreds of case studies and press reviews, and fully-functional evaluations.
The Smart Choice for Text Retrieval® since 1991, the dtSearch product line has over 25 search options for instantly searching terabytes of text. Along with enterprise and developer text retrieval, the company has its own document filters, offering parsing, extraction, conversion and searching of a broad range of data formats. Supported data types encompass databases, website data, popular “Office” formats, compression formats, and emails with nested attachments. dtSearch developer SDKs span multiple platforms. The company has distributors worldwide with coverage on six continents. |
 |
dtSearch 7 Network with Spider dtSearch Network allows for instant text and field searches across an enterprise network
The built-in Spider can expand the scope of the searchable database beyond "local" data to remote web-based content
|
Following are some key features of these products:
- Terabyte Indexer. dtSearch Desktop and Network can index over a terabyte of text in a single index, spanning multiple directories, emails and attachments, online data and other databases. The products can create and search any number of indexes. Indexed search time is typically less than a second, even across terabytes of data.
- Enterprise Searching. The dtSearch product line offers efficient multihreaded searching, with no limit on the number of concurrent search threads. Even with many simultaneous dtSearch Network searches across a very large indexed database, concurrent search time is typically under a second.
- Federated Searching and the dtSearch Spider. dtSearch Desktop and Network products provide federated searching across any number of directories, emails (with nested attachments), and databases. The dtSearch Spider adds local and remote, static and dynamic online content to a search. The Spider can index sites to any level of depth, with support for public and private or secure online content, including log-ins and forms-based authentication. dtSearch products support integrated relevancy ranking with highlighted hits across both online and offline data repositories.
- 25+ Search Options and International Language Support. dtSearch products offer over 25 search types, including special forensics search options. For international language coverage, dtSearch products support Unicode, including support for right-to-left languages, and Chinese/Japanese/Korean character options.
|
| Instantly Search Terabytes
Includes Document Filters
- The dtSearch product line can instantly search terabytes across an Internet or Intranet site, network, desktop or mobile device.
- dtSearch products also serve as tools for publishing, with instant text searching, large data collections to Web sites or portable media.
- Developers: add dtSearch instant searching and data support to your application.
 dtSearch document filters support a broad range of data: dtSearch document filters support a broad range of data:
- MS Office formats through current versions (Word, Excel, PowerPoint, Access, OneNote, including files saved from Office 365)
- Other “Office” and compression formats (RAR, ZIP, GZIP, TAR), SPL, PDF (including many encrypted PDFs), and PDF Portfolio
- Exchange, Outlook, Thunderbird and other popular email types with multilevel nested attachments
- Public and secure web data (HTML, XML/XSL, PDF, ASP.NET, CMS, PHP, SharePoint, etc.)
- Other databases (XBASE, CSV, etc.) plus NoSQL and SQL data with BLOB data (through APIs)
Over 25 full-text and metadata search features
- Efficient multithreaded searching with no limit on the number of concurrent search threads
- Federated searching and other basic search options
- Easy multicolor hit-highlighting
- Forensics-oriented search options (hash support, credit cards, etc.)
- Extensive international language support
- Faceted search or “drill down” category searching (through APIs)
- Granular search results filtering with multiple classification options (through APIs)
APIs for C++, Java and .NET
- Includes native 64-bit versions
- Developer articles on Azure, AWS, faceted search, etc.
- Document filters "only" licenses available
The Smart Choice for Text Retrieval® since 1991 |
|
Document Filters and Supported Data
Document filters overview. dtSearch products embed dtSearch’s
proprietary document filters to support a broad range of data types.
- For all supported data types, support covers
parsing, indexing and searching of retrieved full-text and metadata.
- For all supported data types, support also
covers display of metadata and full-text data with
highlighted
hits. (Typically, dtSearch does this following dtSearch’s own
automatic, built-in conversion of the data to HTML.)
- For many supported data types, display also
includes integrated image display along with
highlighted hits.
Supported data types. dtSearch’s proprietary document
filters support parsing, indexing, searching and display with
highlighted hits
of text and metadata across a broad range of data types.
-
 Web-ready content: supports
integrated images and text in HTML, XML/XSL, PDF, ASP.NET, CMS, PHP, SharePoint, etc. Web-ready content: supports
integrated images and text in HTML, XML/XSL, PDF, ASP.NET, CMS, PHP, SharePoint, etc.
- Other databases and data sources:
supports XML, Access, XBASE, CSV, etc.; dtSearch Engine APIs support NoSQL and SQL-type
databases, along with the full-text of BLOB data; dtSearch Engine APIs also support disk
images, network data streams and other non-file data.
- MS Office formats: supports
integrated browser-ready image and text in Word (RTF/DOC/DOCX), PowerPoint (PPT/PPTX),
Excel (XLS/XLSX), Access (MDB/ACCDB) and OneNote (ONE); support includes
documents saved from Office 365.
- Other “Office” formats, PDF and
other printer formats, compression formats: supports other “Office”
suite formats; EMF Spool (SPL) files; compression formats like RAR, ZIP,
GZIP and TAR; PDF, PDF Portfolio, and many encrypted PDFs.
- Emails and attachments: supports integrated browser-ready images, text and
attachments in Outlook/Exchange (PST/OST/MSG) and Thunderbird (MBOX/EML);
support includes emails saved from Office 365.
- Recursively embedded objects:
supports recursively embedded objects and images in supported email types
and MS Office formats. For example, the dtSearch document filters would
support an email attachment consisting of a ZIP container including both a
PDF and an Access database, where the latter also includes an embedded
PowerPoint with embedded images.
- Full list of supported document types.
Federated searching and
the dtSearch Spider. dtSearch products provide federated search across
any number of directories, emails (with nested attachments), and databases.
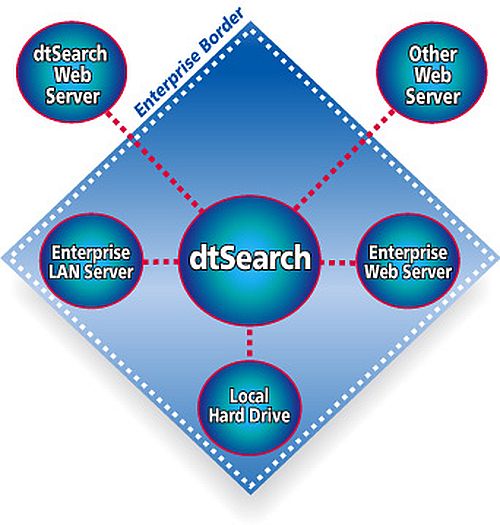
The dtSearch Spider adds local and remote online content to a search. The Spider
can index sites to any level of depth, with support for public and secure online
content, including log-ins and forms-based authentication. dtSearch products
provide integrated relevancy ranking with
highlighted
hits across both online and offline data. Note: for developers, the
Spider is presented as a .NET API.
Document filter APIs.
All developers APIs (C++, Java and .NET through current versions) make available
to developers dtSearch’s text parsing, extraction, conversion and
hit-highlighting capabilities.
- An “object extraction” API lets developers
navigate through the structure of each embedded object as a hierarchy, and
optionally extract each object, such as an image in an MS Word file embedded
in an MS Access database, compressed and attached to an email.
- General dtSearch Engine licenses include the
document filters along with dtSearch indexing and searching functionality.
- The document filters are also available for
separate license for developers requiring text parsing, extraction and
conversion “only,” without search.
|
 |
|
dtSearch Web
with Spider —
Add instant, concurrent
searching of terabytes of static and dynamic online data.
- dtSearch Web includes HTML5 templates for
publishing instantly searchable data to an Internet or Intranet site, all
with no programming required.
- The Spider can expand the scope of a site's
searchable database to include other remote web data.
dtSearch
Engine (all versions) — Add dtSearch’s proven
“industrial-strength” searching and broad data support to your application.
- The dtSearch Engine covers a wide variety of
different platforms (see top of page).
- The dtSearch Engine also works on cloud
platforms like Azure and AWS.
- SDKs include native 64-bit APIs for .NET,
C++ and Java.
- A cross-platform .NET Standard/Xamarin/.NET
Core API is also available.
- See also
developer
tutorials on a wide range of topics, including a walk-through the sample
code for the ASP.NET Core demo.
|
Search Features —
International Languages
|
|
   Unicode
Support Unicode
Support
- Unicode support allows for indexing
and searching of non-English text, including every character set
supported by the Unicode standard.
- In addition to Unicode support,
dtSearch offers extensive alphabet customization options.
- See
Unicode FAQ for more technical information.
- For a general Unicode overview, see
Unicode and Text Retrieval white paper.
Language-Neutral Search Options
- The following search options work
automatically on text in any language:
fuzzy
(adjustable from 0 to 10);
natural
language with automatic relevancy-ranking;
variable term
weighting;
phrase;
boolean
(and/or/not);
proximity and directed proximity;
wildcard;
macro;
numeric range;
and fielded
data (alone or combined with full-text searching).
- See also
forensics
search options.
Language
Extension Packs
- Supplementing the dtSearch product
line’s built-in Unicode support, dtSearch provides
Language Extension Packs covering expanded international
language noise word lists, stemming rules and synonym rings.
- The dtSearch product line includes
an English language noise word list and stemming rules (to find
words such as learn, learned, learns,
learning, etc. that are linguistically related). The Language
Extension Packs provide noise word lists and stemming rules covering
over 25 different languages.
- The dtSearch product line includes
an English language thesaurus for synonyms and related words, with
an option to add custom user-defined synonym rings. The Language
Extension Packs also offer a User Thesaurus Plus feature covering
pre-defined synonym rings in various international languages.
- Licensing: dtSearch Corp. can add
the Language Extension Packs onto a signed dtSearch developer
license.
- More information on the
Language Extension Packs
Chinese,
Japanese and Korean Text With No Word Breaks
- Some Chinese, Japanese, and Korean
text does not include word breaks. Instead, the text appears as
lines of characters with no spaces between the words..
- Because there are no spaces
separating the words on each line, dtSearch sees each line of text
as a single long word.
- To make this type of text
searchable, enable automatic insertion of word breaks around
Chinese, Japanese, and Korean characters, so each character will be
treated as single word.
- dtSearch Desktop/Network:
In Options > Preferences > Letters and Words, check the box to
“Insert word breaks between Chinese, Japanese, and Korean characters
in text.”
- dtSearch Developer API: set
dtsoTfAutoBreakCJK in Options.TextFlags.
Language
Analyzer API Integration
- In addition to the extensive
alphabet customization options available across the dtSearch product
line, the dtSearch Engine also includes a
Language Analyzer API that can be used to integrate
morphological analyzers and custom or dictionary-based word breakers
into the dtSearch Engine indexing process.
- The dtSearch Engine also includes an
API for substituting a non-English language thesaurus for the
existing English-language one.
Basis
Technology’s Rosette® Linguistics Platform Integration
- The Rosette Linguistics Platform
helps unlock the meaning of unstructured text by determining the
language, and identifying the basic linguistic features and
structure. Relying on code that is unique to each particular
language, Rosette results in highly accurate Chinese, Japanese,
Korean, and other international language morphological analysis..
- The Rosette Linguistics Platform
integrates with dtSearch search functionality through the dtSearch
Engine’s Language Analyzer API. Essentially, the dtSearch Engine
API passes blocks of Unicode text to the Rosette Linguistics
Platform and accepts back words to index.
- For more details on how the two
products work together, including a chart detailing the different
steps involved in the dtSearch Engine and Rosette API integration,
please see
dtSearch and Rosette Full-Featured International Search PDF
white paper.
|
|
|
 |
|

|
|






